I'll just use primary-backup for my database - well, think twice
Introduction
Some time ago I heard about DSLabs from a review on The Morning Paper blog and found it a great resource to learn distributed systems concepts by doing.
Recently I started more seriously to implement solutions from the labs in there.
I finished the primary-backup lab, but passing all the unit-tests was surprisingly hard, with about 3 re-writes needed in the process.
And the resulting implementation, while providing single-copy consistency, is both inefficient in performance and lacking in availability (as expected after all, given CAP).
This got me thinking more about this mechanism I used to take for granted before:
- Does a relational database look good for the use-case?
- OK, will throw a primary-backup mechanism in there and our availability problems will be solved for free, no downsides from just using a single server.
- Well, not so simple.
A good image to describe a primary-backup architecture can be found in the AWS RDS (Relational Database Service) documentation, where it is called primary-standby or multi-AZ deployment:
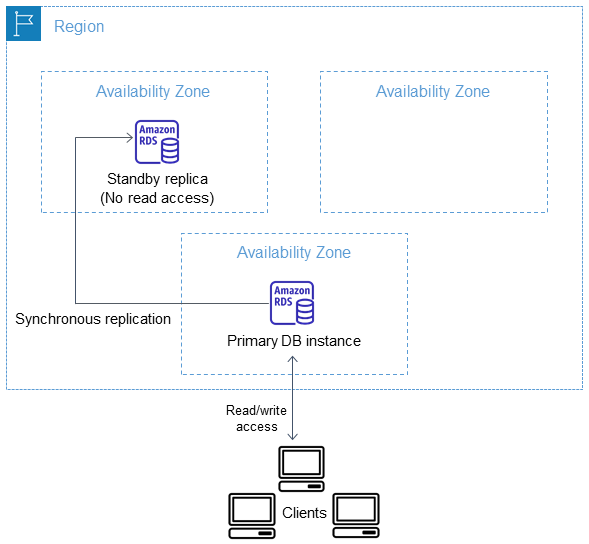 Source: Multi-AZ DB instance deployments
Source: Multi-AZ DB instance deployments
Problems
Some problems to address with a primary-backup mechanism providing single-copy consistency:
- Before the primary returns OK for a client write, it must wait confirmation that the write reached the backup. This ensures no data loss if the primary dies. Downsides: performance loss from synchronous replication; possible bugs from protocol complexity: keep retrying until the backup answers, but be prepared to switch to a different backup if the current one died, to not get stuck.
- Before the primary returns OK for a client read, surprisingly it must also wait confirmation from the backup. This is to prevent split-brain, when both the primary and the backup think they are primaries. Again performance loss.
- The primary must send the operations to the backup in exactly the same order it received them. This maintains single-copy consistency. A simple implementation may handle operations one by one, with severe performance loss.
- A backup cannot upgrade to primary until it finished receiving the entire state from the old primary. It must wait and hope that even if the old primary appears as dead to the system, it is still sending the state. But if the primary really died, the alternatives do not look good: remain stuck, or start with incomplete state, thus data loss.
- The network is unreliable. The messages get lost, delayed, duplicated (replayed). You don’t want the backup applying old state because it received a message from the “past”. And what does the backup do when it receives a message from the “future”?
- While this is not a lab concern, in real-world, for a newly started backup, how do you transfer efficiently say 3TB of state from the primary to the standby, while having the primary under heavy load? How much time will the primary and thus the entire system be unavailable for handling operations?
Solutions
The lab points to Viewstamped Replication (VR) as a solution to improve on the above-mentioned downsides.
VR can maintain multiple backups, and backups can talk to each other. The primary and the backups are called replicas.
Thus, VR can be scaled to improve availability by adding replicas, and the system remains available as long as there is a quorum of healthy replicas.
Multiple backups means the primary must now talk to even more machines for each client operation, but the good news is that the talking to backups can be done in parallel, with minimal overhead from the single backup case.
Several optimizations mentioned in the VR paper address the problems mentioned above:
- Receive the application state on a recovering replica from any other replica, not just the primary. A Merkel Tree can be used on each replica for efficient state transfer with large application states.
- Clone the disk of an up-to-date replica and install it on a replica that has been disconnected for too long - now that’s an interesting one for the 3TB concern above.
- Batch commands sent from primary to backups to improve the severe performance loss from handling commands one by one mentioned above.
- Use leases to implement efficient reads from the primary only, without the danger of split-brain.
- Relax consistency requirements to implement efficient reads from backups as a load-balancing mechanism, while maintaining causality.
AWS RDS primary-backup solutions
Let’s visit the AWS RDS primary-backup solutions in light of the previous findings:
- Multi-AZ DB instance deployments - single backup, synchronous replication, just like in the lab. Knowing what I know now, I would strongly avoid it. And the AWS documentation does warn about “increased write and commit latency”. But without awareness of possible issues and explicitly looking for limitations, it is easy to miss the warnings.
- Multi-AZ DB cluster deployments - two readable backups, asynchronous replication, thus better performance. But asynchronous replication means possibility of data loss, if primary dies while there is replica lag. Thus, I would still avoid it.
- Aurora DB cluster: Aurora decouples compute (the db instances) from storage. The storage is shared between the primary and the read replicas. Any writes from the primary are seen nearly instantly by read replicas, thus any read replica can quickly promote to primary. The hard part of synchronous state replication is pushed to the storage layer, with a good description in Introducing the Aurora Storage Engine. The data is replicated to 6 storage nodes. The storage can serve reads if there are at least 3 nodes up and writes if there are at least 4 nodes up. Quorum usage and replicas recovering from surrounding replicas are ideas we also saw in the Viewstamped Replication protocol. This is the option I would recommend. The main reason is that the system has a single mode of operation (storage replication happens regardless if you use read replicas or not), and thus performance is predictable.
Takeaway
A primary-backup mechanism will not solve your database availability problems for free. It comes with trade-offs in terms of accepting and dealing with performance loss, availability loss under network partitions, even data loss. Study carefully the primary-standby documentation of your database and hunt for downsides.
DSlabs is the best resource I found so far to learn distributed systems concepts and algorithms by doing instead of just reading. Give it a try if you have an interest in distributed systems.